
Let’s face it – if you’ve ever worked with VoIP service monitoring metrics, you’ve seen it. Latency, delay, round trip time… these performance metrics pop up everywhere. From detailed RFQs to international standards like ITU-T Y.1540 defining IP packet transfer delay, G.114 covering one-way transmission time, or GSMA specifications for round-trip and one-way delay measurements – they’re omnipresent.
But here’s the thing that’s been nagging me for quite a while: why is everyone so obsessed with data that is fundamentally problematic to measure accurately? Every time I see these requirements cross my desk, I can’t help but wonder if we’re all chasing the wrong indicators.
In this article, we’re going to challenge conventional wisdom and explain why some commonly requested metrics might be leading your operations team down a rabbit hole of misleading data.
You’ll discover: Why accurate latency measurement is practically impossible in real-world networks; How focusing on delay metrics can lead operations teams down the wrong path; What actually impacts user experience in voice communications; Which metrics you should monitor instead to effectively improve voice quality
The Latency Labyrinth: What Are We Actually Measuring?
Before we dive into why latency metrics might be pointless, let’s clarify what we’re talking about. According to Wikipedia, latency is “a time delay between the cause and the effect of some physical change in the system being observed.” Pretty broad, right?
In networking terms, it’s essentially the time it takes for a packet to travel from point A to point B. You send a packet from one end, and it eventually pops out on the other. The time difference between those events is what we’re measuring.
But wait – is latency different from delay? This question sent me down a rabbit hole, and honestly, I’m still not entirely convinced there’s a clear distinction. ChatGPT says “latency is a specific type of delay that refers to the time it takes for data to travel through the network.” Thanks for clearing that up (not really).
Perhaps more authoritatively, ITU-T G.104 provides guidance on “the effect of end-to-end one-way delay (sometimes termed latency).” So while there’s a tendency to use “latency” specifically for one-way network delay as opposed to round-trip metrics, for simplicity’s sake, we’ll treat “delay” and “latency” as synonyms throughout this article.
Now, the million-dollar question: Why do we care about this metric so much?
It’s widely accepted that user experience suffers when one-way delay exceeds 150 milliseconds. The graph from the G.107 E-Model (which relates to R-Factor/MOS measurements) shows that voice quality gradually declines as delay increases, with a significant drop around the 150-200 millisecond mark.
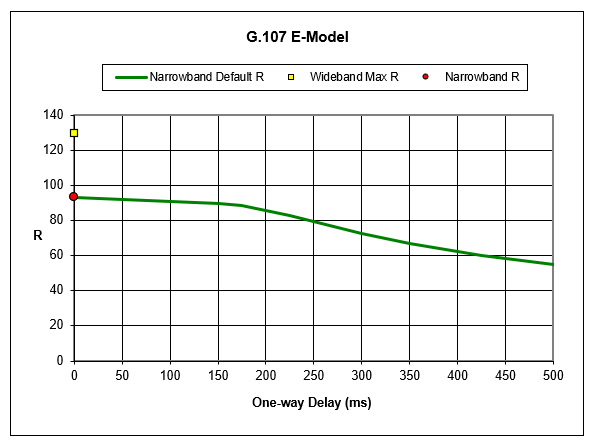
This drop happens because beyond this threshold, participants in an interactive conversation start to interrupt each other. They interpret the delay as the other party not responding, so they jump in – creating that awkward “Sorry, you go ahead… No, you go ahead” dance, that you may still remember from those satellite calls with your overseas aunt in the last century.
The industry standard has therefore been simple: keep one-way delays under 150 milliseconds, and your users should be happy. Sounds straightforward enough, right?
If only it were that simple. As we’re about to see, there are some fundamental problems with focusing on latency measurements that make this seemingly clear-cut metric much more complicated – and potentially misleading – than it appears.
The Delay Domino Effect: Understanding VoIP Latency Components
When we talk about delay in VoIP communications, we’re not dealing with a single, unified metric – we’re actually looking at a complex chain of sequential delays that stack up to create the total end-to-end experience. Think of it as a relay race where each component hands off the baton while adding its own time to the clock.
Let’s break down this relay team:
Starting at the sender’s end (a phone or VoIP device), we encounter our first two delay sources:
- Codec delay: The time required for the codec algorithm to process audio samples and prepare them for transmission
- Packetization delay: The time needed to gather all samples required for a complete packet
For a typical 20-millisecond packet rate, these two components alone can contribute around 20 milliseconds to your total delay budget.
Once the packet is ready to leave the device, we meet:
- Serialization delay: The time it takes to put the entire packet onto the network link, which varies depending on available bandwidth
Now our packet is traveling through the network, where it faces:
- Propagation delay: The time required for bits to physically travel across the network medium, roughly approximated by the speed of light (though actual speeds vary by medium)
- Processing delay: The time needed by each network element (router, switch) to receive the packet, determine what to do with it, and prepare it for forwarding
- Queuing delay: If the outgoing link is busy, packets must wait in a queue, adding unpredictable delays that can fluctuate dramatically based on network conditions
Finally, at the receiving end:
- De-jitter buffer delay: Receivers maintain buffers to compensate for network jitter, ensuring smooth audio playback – but at the cost of additional delay
- Decoding delay: The (typically minimal) time required to convert the received packet data back into audio samples
This complex interplay of delay components presents our first major challenge with latency metrics: we’re not measuring a single, stable value. We’re dealing with a composite of multiple factors, many of which are outside the control of any single network segment or service provider.
What’s more, these components behave differently. Some are fixed (like codec delay), some are variable but predictable (like serialization delay), and others are completely dynamic and unpredictable (like queuing delay).

And this is just the beginning of our problems with latency measurements. As we’ll see next, even if we could reliably track all these components, actually measuring end-to-end latency in production environments presents its own set of nearly insurmountable challenges.
If it is a problem, then how do we measure it?
The holy grail in the VoIP world is measuring one-way delay – the actual time it takes for a packet to travel from source to destination. In principle, this sounds deceptively simple: note down the time (t₀) when the packet leaves the sender, record the time (t₁) when it arrives at the receiver, and subtract to get your one-way delay (OWD = t₁ – t₀).
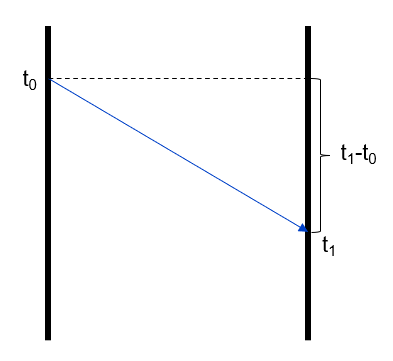
Easy, right? Not so fast.
This seemingly straightforward calculation runs into a major technical hurdle: clock synchronization. For one-way delay measurements to be meaningful, the clocks at both ends need to be synchronized with extreme precision – for VoIP services we’re talking millisecond accuracy or better. And here’s the kicker: standard Network Time Protocol (NTP) synchronization simply isn’t sufficient for this level of precision.
You might achieve adequate synchronization in a controlled lab environment or maybe within your own LAN using specialized hardware, but as soon as you cross network domains or try to measure real-world traffic, all bets are off. The time differences between devices becomes significant enough to render your measurements unreliable.
Yes, there are technically ways to achieve the required synchronization – GPS-disciplined clocks, atomic references, or specialized timing hardware – but these solutions are expensive, complicated to implement at scale, and simply not practical for most operational environments. They’re certainly not applicable across the disparate networks that typical VoIP traffic traverses.
So right off the bat, we have a fundamental challenge: the most direct and meaningful measurement of delay – one-way delay – is practically impossible to obtain with sufficient accuracy in the real world. That’s a major problem when organizations and standards bodies keep asking for this metric as if it’s something you can just pull from your monitoring system.
RTD – A Practical Approach That Can Still Lead You Astray
Given the challenges of one-way delay measurement, the industry has turned to round-trip delay (RTD) as defined for example in RFC 3550. This approach uses timestamps in RTCP packets, with one-way delay typically approximated as RTD divided by two.
It’s a practical solution that doesn’t require precise clock synchronization, but it introduces its own set of problems:
- Forward and return paths might not be symmetrical
- Traffic congestion could affect only one direction
- Many devices implement RTCP stacks incorrectly
- RTCP packets might be blocked in the network
- Some service standards don’t even allow RTCP
These aren’t just theoretical concerns. Let me share a revealing case from one of our customers:
A VoIP service provider was receiving complaints from many Voice over LTE customers about “choppy voice” and “difficulties with call setups.” Their monitoring tools, relying on RTCP measurements, reported alarming delays of over one second and some packet loss.
For months, their operations team focused all their troubleshooting efforts on tracking down the source of this seemingly massive delay problem, examining the air interface and packet core components of their network.
But something didn’t add up. If customers were truly experiencing one-second round-trip delays, they wouldn’t be complaining about “choppy voice” – they’d be describing the conversation as impossible, like “talking to the moon.” The reported symptoms didn’t match the supposed diagnosis.
When we deployed our monitoring equipment, we quickly identified the actual root cause: an underprovisioned link causing high packet loss and jitter. Once this was fixed, the voice quality improved dramatically – the MOS distribution graph flipped from showing 85% of calls with poor quality (below 3.1) to 81% with excellent quality.
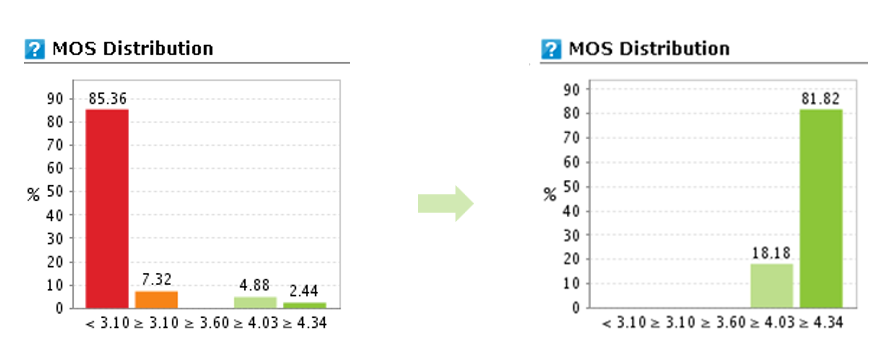
Here’s the kicker: that massive one-second delay reported by their tools? It wasn’t real. The jitter on the network was affecting the RTCP packets used for delay calculation, causing wildly inaccurate measurements. The operations team had spent months chasing a ghost, all because they trusted a flawed metric.
This experience is why Qrystal flags RTCP delay measurements above 500ms as potentially untrustworthy – we’ve seen too many cases where technical limitations or implementation issues in endpoint devices lead to completely misleading delay reports.
The lesson? Even the “practical” solution for measuring delay in VoIP networks can lead you dangerously astray.
But Is Delay Even an Issue?
Let’s take a step back and ask a more fundamental question: Is delay actually the problem we should be worrying about?
Consider this real-world example: The distance between Aachen, Germany and Perth, Australia is approximately 14,000 km. Light travels this distance in about 50ms. A traceroute between these locations shows 26 network hops and roughly 260ms round-trip delay.
If we add typical VoIP-related components (packetization, jitter buffers, etc.) of about 120ms and divide by 2 for one-way calculation, we get approximately 210ms mouth-to-ear delay. Yes, this exceeds our theoretical 150ms threshold, but it’s not catastrophic.
In 20 years working in the VoIP business, I’ve never seen or heard of actual issues with end-to-end VoIP delay. Not once. Every time latency appeared to be the culprit, we were chasing phantoms.
Even if: what can you possibly do about it? You can’t lay a direct optical connection between every point on the globe. You can’t change the speed of light. Some delay is simply physics.
Even if there were genuine delay issues, there’s hardly anything you could do about it from an operational perspective. That’s the key point here: latency is an engineering or planning topic, not an operational issue. Many of the delay components are fixed by design or physics, not something you can adjust in daily operations.
What actually impacts user experience? Delay variations – also known as jitter.
VoIP requires a continuous flow of packets to maintain audio quality. Variations in delay lead to gaps in the audio and/or force receivers to implement larger de-jitter buffers. And here’s the irony: those larger buffers actually increase overall delay. By trying to solve one problem (jitter), you’re making another worse (latency).
These variations are typically caused by buffering network elements – things that you can actually monitor and fix within your network. Congested routers, overloaded switches, and poorly configured QoS policies are the real culprits behind most perceived “delay problems.”
So my recommendation? Forget about latency and delay metrics for operational purposes. Yes, include them in RFQs and standards if you must, but recognize that for actual day-to-day operations, they’re practically impossible to measure reliably and accurately. The dominant factors are often not under your control anyway.
Focus instead on what you can change: jitter and packet loss. These are the metrics that will actually help you identify and resolve the issues that truly impact your users’ experience – and stop you from wasting time chasing phantoms.