Have you ever found yourself at the mercy of network element vendors, grappling with severe issues while they deny any wrongdoing, play ignorant, or leave you struggling for extended periods? If so, you’re not alone. Many organizations have faced the daunting challenge of relying on vendor data that doesn’t measure up to scrutiny.
In this article I will delve into real-life case studies where customers encountered significant challenges, each one woven with the common thread of protracted struggles with network element vendors unwilling to concede their errors until backed into a corner – confronted with irrefutable evidence, often provided by Qrystal, but I’ll circle back to that a bit later. No more spoilers for now.
Let’s explore the vital lessons learned from these encounters and understand why blind trust in vendor data can lead to extended downtimes, heightened frustration, and potential harm to your business.
Case #1: One Morning in a Major Bank – An Unfolding Disaster
It’s 8:00 AM, the perfect time for the CEO to make an announcement. And not just to a selected group of people, but to all 1,500 HQ employees. Picture this – back in the day when Zoom and Teams were just futuristic dreams, we relied on good ol’ telephone conferences. No video calls, just voices buzzing through the phone lines. Now, here’s where it gets interesting. Fifteen minutes into the call, disaster strikes. The audio goes haywire, and the CEO’s important message is lost in a sea of technical glitches. If you’ve ever been on the operations side of things, you can imagine the chaos. Not fun.
Once the call ends, everything seems to have gone back to normal, as you can see from the image below.
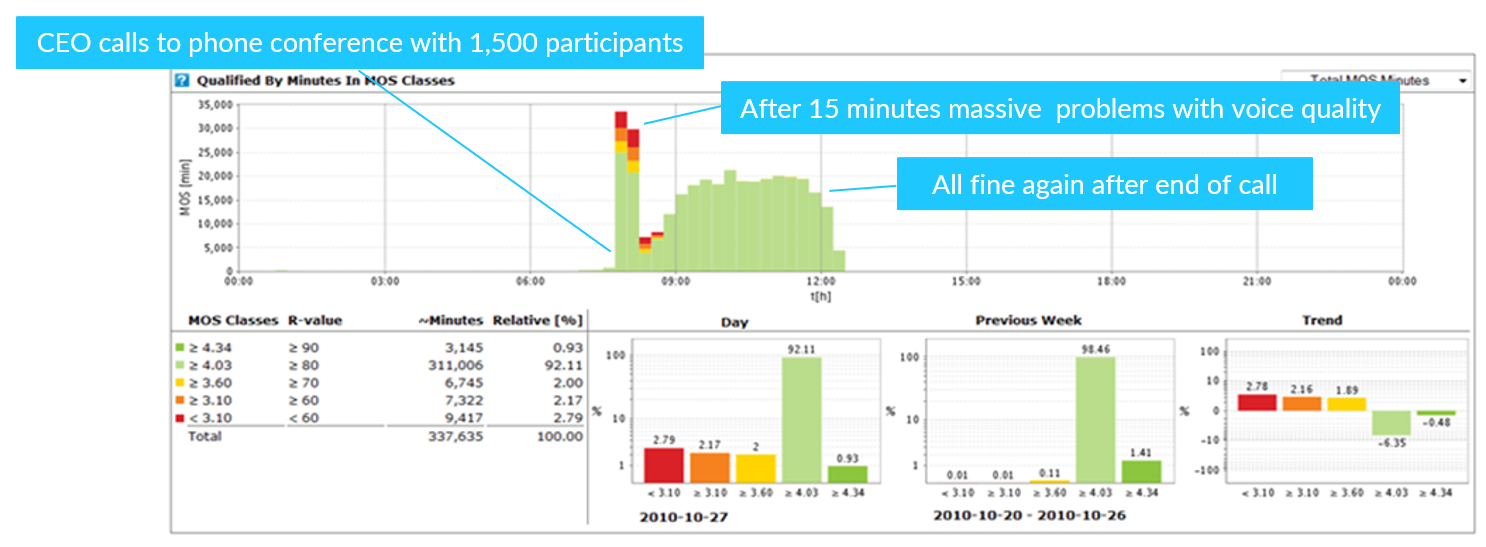
Back to the operations people. They started to scramble and dig into the problem. Here’s what they saw:
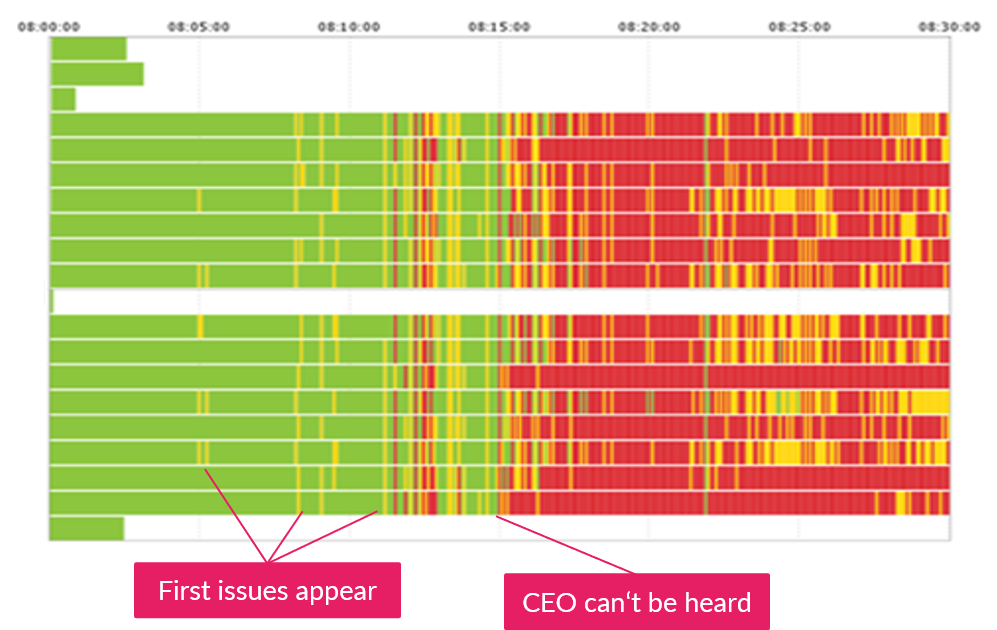
This picture is a confusing one – a bunch of lines representing RTP streams, each stripe showing 5 seconds. Green is good, red is trouble. You get the drill.
The waves of issues hit at 5, 10, 12, and 15 minutes into the call. Everyone stuck around, trying to hang on to every word the CEO was saying. Little did they know that everyone was suffering from the same problem, and little did the CEO know that he was increasingly talking into the void.
The analysis conducted by operations revealed that all RTP streams sent by the firewall looked like this:
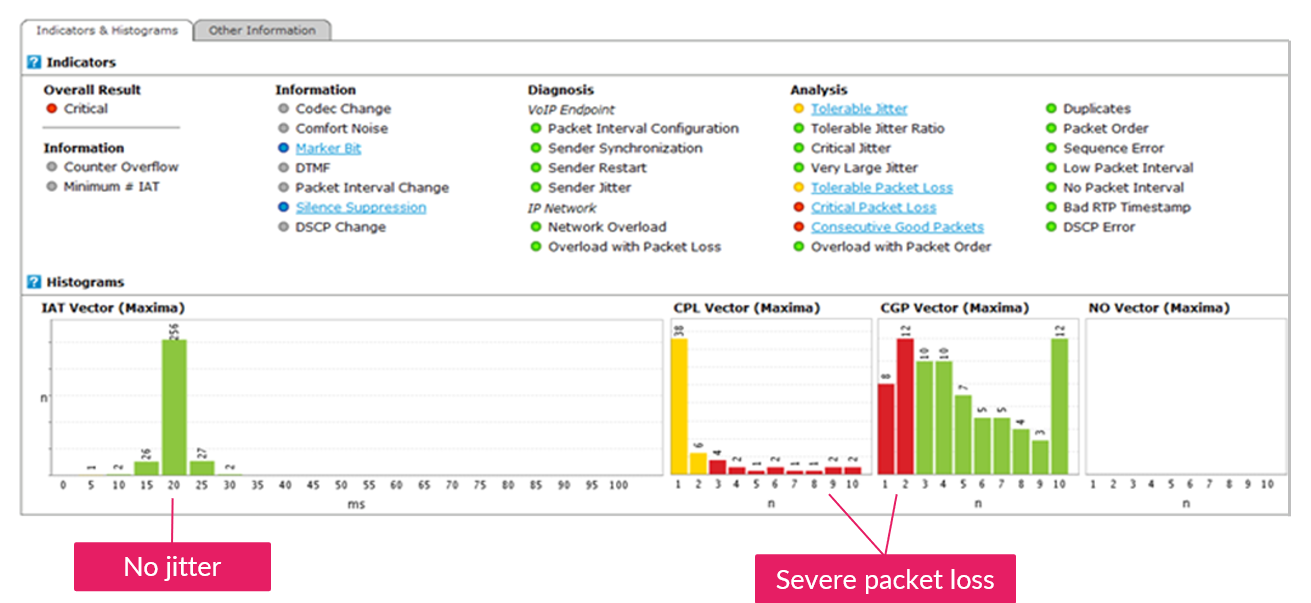
It’s evident that packets arrived in 20 millisecond intervals, so no jitter. But there’s a substantial loss still: burst loss with 10 packets or more lost in sequence and very few packets arriving in between. This severe loss resulted, as we already know, in no one being able to hear the CEO’s important announcement.
Time to call in the cavalry – the firewall vendor, CheckPoint. The vendor’s response came in quickly: “Yes, the issue is known. The workaround is to just switch off the SIP Application Layer Gateway”!! Say what? A feature they charged for, and no heads up about potential hiccups.
That’s when the head of operations reached out to us, thankful for still having his job, after the CEO realized that he was practically talking to himself. This case could have taken a different turn from the monitoring perspective if there was no hard evidence to provide to CheckPoint, who had no other choice but to admit there was indeed a problem on their end. Lesson learned – whether it’s CheckPoint or any other tech wizard, where there’s software, there’ll be bugs. Always arm yourself with hard evidence to make them take responsibility.
Case #2: Ghost Voices
This one is about a tier-1 fixed network provider dealing with a barrage of tickets from seriously concerned enterprise customers. Why? Because these folks were hearing voices. No, not the psychotic kind, but the voices of complete strangers in their calls. You can imagine the annoyance: if they can hear others, who knows if the tables are turned? To top it off, one of the peeved customers was a political party, so you can guess how fast things went from 0 to 100 in the complaint department.
That’s when the network provider reached out to us. At first, we were scratching our heads. Ghost voices, cross-talk, whatever you want to label it, was a regular issue in the analog world. Electric signals could spill over, and you could accidentally eavesdrop on someone else. But in the IP world? How does a voice signal encoded in one packet magically spill into a different call? Total head-scratcher. But hey, we love a good mystery, so we took it on.
We dove into all the reported calls, expecting some SIP and RTP data anomalies, but no dice. All the theoretical mumbo-jumbo about “VoIP crosstalk” didn’t hold up. Then came the lightbulb moment – Cisco MGWs were the common denominator in 100% of the reported convos.
The CSP then called Cisco. Guess what? Cisco played hard to get. No action until there’s proof, they said. They wanted a WireShark trace, or no ticket, no investigation. So, we rolled up our sleeves, set up a packet recording job in Qrystal to record calls of a friendly customer and patiently waited. One day we finally struck gold: Ghost voices – or the voices of another conversation – loud and clear.
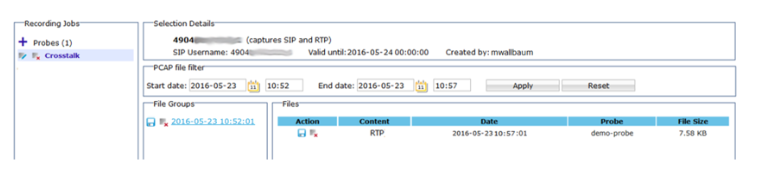
Another call to Cisco, armed with hard proof this time. Lo and behold, they admitted it was an old bug that hasn’t been fixed and wasn’t even planned to be fixed. Their grand solution? “Just reset your media gateways every 466 days.”
Case #3: An IMS Full of Surprises
Alright, buckle up for the saga of a customer diving into the world of a new IMS from Mavenir, and boy, did they get more than they bargained for. And Mavenir’s response to the plethora of issues? They basically shrugged off every problem like it was no big deal. Let’s jump into the details:
So, this mobile operator rolls out Mavenir’s shiny new IMS core in their private cloud. Picture this – subscribers migrating from the old Ericsson system to the fresh Mavenir setup, and lucky us, we’re monitoring both. Midway through this techno tango, VoLTE users on the Mavenir platform start griping about silent and dropped calls. Mavenir’s response? Classic denial mode. Independent investigations were launched by both Mavenir and the operator, but surprise, surprise, Mavenir’s data doesn’t align with the actual issues reported in the support tickets.
Here’s what our investigation came up with:
Issue #1 – Silent calls:
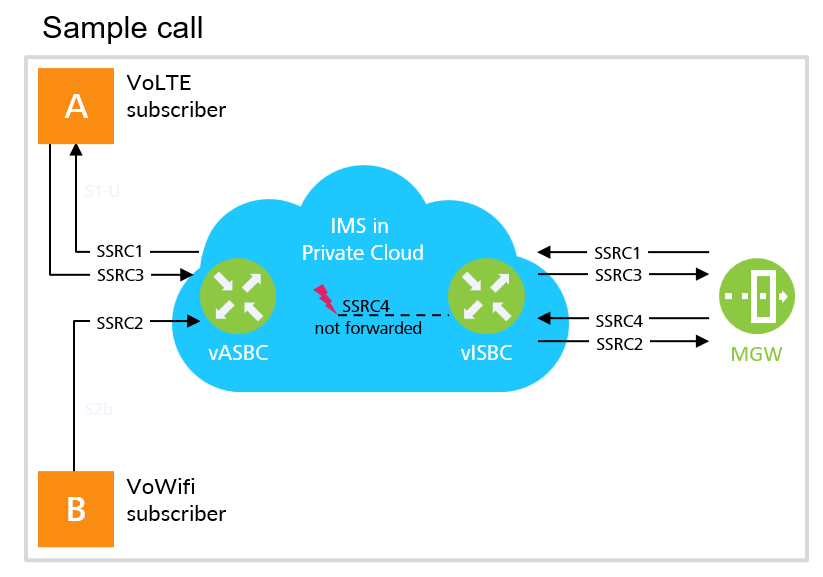
Subscribers were complaining about audio going silent in one direction. Investigation reveals a distinctive pattern. We were monitoring the private cloud that appears in blue in the image below, on the access side and on the core side.
Party A placed a call, got early media from the media gateway (SSRC1), passed through the IMs cloud, and transferred to the VoLTE subscriber.
Next, Party B, who is a VoWiFi subscriber sent SSRC2 toward the IMS private cloud, to be transferred to Party A.
Same thing with the SSRC3, coming from Party A, now that the call was established.
But this SSRC is terminated at the media gateway and should lead to a new RTP stream being sent from the media gateway to Party B. While the media gateway does that (SSRC4), that RTP stream never popped out from the IMS private cloud. Now the data was clear. We had several examples of this pattern. We had the receipts, but Mavenir kept insisting everything was working well.
Issue #2 – Wrong data on dropped call ratio:
Mavenir reported a Dropped Call Rate (DCR) of around 0.1%, based on their measurements. But our own measurements told a different story:
- ~ 0.4% for Mavenir IMS and
- ~ 0.3% for Ericsson IMS
Our numbers matched up with the user complaints, not Mavenir’s story.

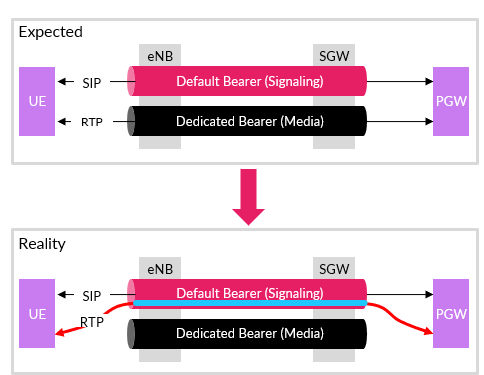
Issue #3 – Call drops due to wrong bearer:
Why were there more dropped calls with Mavenir than Ericsson? Enter the ‘RTP timeout’ party crashers. Turns out, the media was using the wrong bearer, wreaking havoc on the calls. If you’re familiar with VoLTE, you know that the SIP signaling goes over the default bearer, between the PGW and the UE. To establish a call, a dedicated bearer is set up, which is used exclusively for exchanging the RTP media between the two call parties. That’s the expected scenario.
What we saw in reality was different. A dedicated bearer was indeed set up, but the RTP was sent through the default bearer. That caused the network elements to declare an RTP time out because nothing was coming out from the expected dedicated bearer’s end of the tunnel.
Mavenir confirmed the wrong bearer but denied any real impact on users.
This case is a classic reminder of the importance of having the hard facts, the undeniable proof. Service providers and vendors might not always see eye to eye, especially when it comes to critical KPIs. Sometimes, it’s a clash of interests, and having that evidence handy is your golden ticket.
Case #4: Side-Effects of a Power Outage
Alright, let’s dive into the nitty-gritty of this last tale. A quick power hiccup hits one of the mobile network operator’s Points of Presence (POP). The blackout messes with the cooling system, but kudos to the tech squad – they fix it up within hours, and the site is back on its feet. Easy peasy, right? Well, not quite.
Now the plot thickens. The operations team spots a surge in issues post-power outage. Subscribers aren’t shy about airing their grievances either. Check out the image below – thousands of calls are taking a beating with all sorts of packet losses, due to the fallout from the power hiccup.

Now, the bars in the image? They’re like a visual map of misery, showing the number of minutes things went haywire. The colors? Green is all cool with a MOS better than 4.0, but when it hits red, it’s like a signal for downright awful voice quality.
Ericsson was called in to inspect the media gateway. Surprise, surprise – no issues found. But armed with our data, we play detective and point them straight to the troublesome media gateway card out of the 12, wreaking havoc. Card swapped, and just like magic, service quality bounced back to normal.
This was a simple story, but it could’ve easily been a real brain teaser. Picture this: a massive media gateway, making it harder to play detective and pinpoint the source of the call chaos. From the Ericsson Media gateway’s point of view, everything was rainbows and sunshine – calls accepted and terminated like clockwork. No alarms. But customers? Oh, they were ringing the complaint bell. The kicker here? Only when you peek at the quiet metric does it hit you – the chances of having bad call quality were playing a wild 1/12 game of roulette. Crazy, right?
Wrapping It Up
As we draw the curtain on these tales from the telco operations trenches, one thing becomes crystal clear – the road with network element vendors is often paved with bumps, twists, and unexpected turns. From audio glitches in major bank announcements to ghostly voices haunting fixed network providers, and the surprising hiccups in the world of a new IMS.
What stands out, though, is not just the unique challenges each vendor posed, but the common theme weaving through all these narratives. No matter the vendor, no matter the hardware, bugs and issues are the unwelcome guests at this party.
In a world where network disruptions and downtime can mean serious trouble, blind trust in vendor data is akin to walking through a tech minefield. The stories shared here emphasize a crucial takeaway – having the right data at your fingertips is not just a luxury; it’s your shield against prolonged struggles, potential business harm, and heightened frustration.
As telco operators, you’re often at the mercy of vendors, and when things go south, getting them to own up can feel like pulling teeth. The hard evidence is what can turn vendor denials into admissions and pave the way for solutions.
It’s not just about making vendors take responsibility; it’s about ensuring your network stays resilient, robust, and ready for whatever surprises the tech world throws your way.