“The horse does not eat cucumber salad.” This was one of the nonsense messages Philipp Reis—one of the pioneers in speech transmission—used to demonstrate the capabilities of his “Telephone” apparatus in the 1860s. The message was most likely hardly audible at the other end, yet the technology evolved and became a modern standard of communication.
Today, telephony in its latest incarnation as Voice over IP (VoIP) has become so ubiquitous that individual consumers and enterprises alike expect consistent and excellent availability and voice quality every time they make a call. Therefore, call quality in its broadest sense— encompassing continuous service, audio fidelity, lack of dropped or one-way calls, etc.—is a vital competitive advantage for service providers. In a crowded marketplace, consumers will always find another provider to use.
However, delivering a high-quality voice service with each and every call is a challenge, and service providers have to deal with a variety of issues:
- Struggling with a lack of accurate data on the user experience. By only analyzing call signaling, not the media transport performance, providers lack information on 98% of the VoIP traffic thereby missing valuable data on in-call quality.
- Difficulty obtaining data that is really actionable to help improve the network and service quality.
- Failure to link problems with individual calls directly to their root cause. Many struggle to distinguish between issues created by the network and those created by end devices.
- Trying to improve operational efficiency by reducing the time and expertise to resolve common but tough issues such as dropped calls and silent calls, just to name a few.
- Inability to verify that interconnection partners meet service level agreements (SLAs). This means communication service providers (CSPs) that receive bad traffic from an interconnection partner are often held responsible by the end-user when the fault lies elsewhere.
- Facing challenges related to voice services delivered by different providers using one IP infrastructure, complicating the process of identifying faults and root causes.
- Struggling to leverage cloud benefits without reducing network visibility and compromising user experience.
To help overcome these and other challenges, we compiled a list of seven best practices for voice monitoring that all service providers could benefit from. Whether it’s mobile networks, fixed networks, wholesale networks, or call centers, every operator wants to be in the business of delivering excellent call quality.
The secret to delivering superb voice services lies in effective and actionable voice monitoring.
You can’t find solutions without visibility into the problems in the network. Let’s review some best practices to achieve such superb voice quality monitoring:
1. Divide and Conquer: Using Passive Monitoring to Segment Your Network
VoIP calls traverse multiple network elements transferring data back and forth between the calling and receiving parties. The network path between the two parties typically includes a range of components, including:
- Physical links
- Routers and switches
- Session border controllers (SBCs)
- Media gateways (MGWs)
Any of these network elements can potentially create an issue that degrades service quality, impacting the end-user experience.
The only way to determine which network elements are causing service degradation is to segment the network into smaller parts. A great real-world example of using a divide-and-conquer approach to solving a problem is when we need to look for something that we’ve lost around the house. Instead of trying to search the entire house, we can divide the problem into smaller parts by looking at each room separately.
Without network segmentation, all you know is the sum of every component along the network path adds up to the poor user experience. With probes positioned at different points along the path, you can determine which elements really have a negative impact on user experience.
Modern voice monitoring probes allow you to monitor call streams and signaling messages at different points in the network. You can analyze the signaling through the network and track call-quality metrics associated with the RTP stream, spotting problematic elements and isolating issues that need fixing.
2. Gaining an End-to-End View: Correlating Data on Both the Media and Control Plane Throughout the Network
Correlating data from both the media and control plane during VoIP sessions is critical to understanding call quality. This is a complex task, given that you want to monitor quality at multiple points in the network, and that signaling and media often take different paths. Correlating all data belonging to a call resembles a jigsaw puzzle with many pieces.
New monitoring technologies can identify and characterize media streams even without associated signaling, including early media (ringtones, etc.), in-call codec changes, and streams modified to pass through firewalls and network address translators (NATs). Detecting RTPs outside a call context is key, because SIPs and RTPs can take different paths.
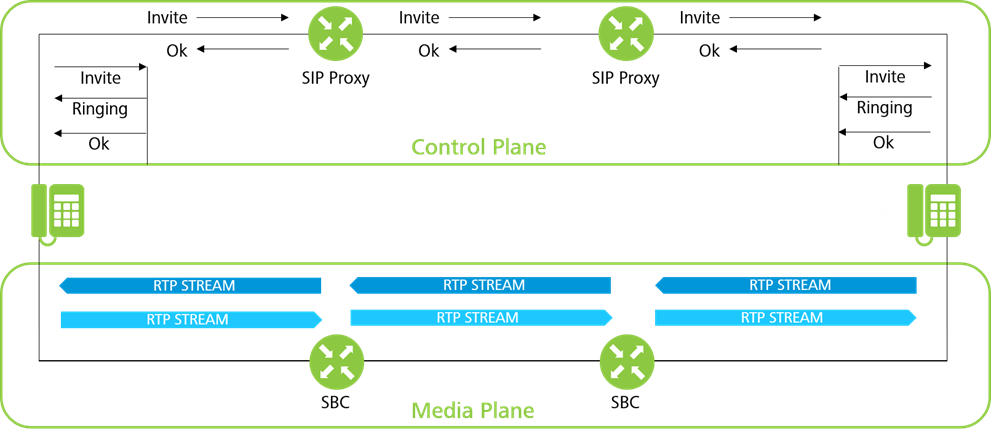
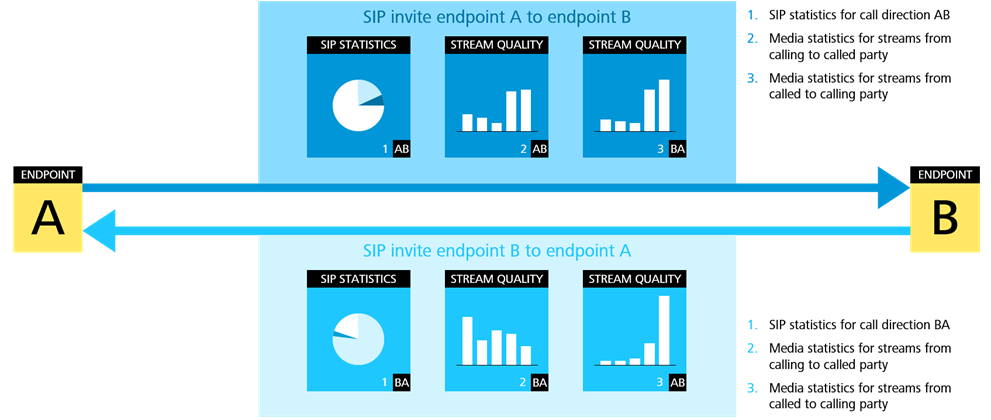
The correlation process matches the local signaling measurements (xDRs) and RTP media streams of a call to create call data records (CDRs), offering a much more detailed view of the user experience. xDRs summarize the call-related SIP signaling at a specific monitoring point, and CDRs contain all of the information from probes distributed across the network. A CDR might have over 300 fields, including:
- Call start time, end time, and duration
- Calling and called party IP addresses
- The codecs used for both call directions
- Hang-up cause
- Metrics related to media quality, such as Mean Opinion Score (MOS), packet loss, and jitter
Voice monitoring probes can now gather all streams and xDRs from the same call, assigning them a specific CDR tag for combined analysis. The media quality associated with a call is determined by the stream with the worst quality on the path. If metrics vary from stream to stream or from xDR to xDR, probes can track the difference for further analysis.
3. Automating Root Cause Analysis: Let Technology Do the Hard Work
Voice monitoring provides the data you need for root cause analysis. However, even with the data on hand, it is still a time-consuming process that requires significant expertise.
Today, service providers can simplify their operations and significantly reduce the time needed for root cause analysis through automation. Common network problems appear in the data with known patterns, i.e., they will affect the SIP and RTP traffic in reproducible ways. With probes continuously monitoring the network, systems can automatically identify common impairment patterns associated with specific issues.
An example of such a pattern is provided by jitter introduced by the RTP sender’s device, not the network. This can occur when the sender’s device transmits packets systematically too early or too late, because its software is unable to maintain the packet rate. This creates a very distinct pattern in the interarrival time of packets. Voice monitoring can automatically detect this pattern and trigger operations to diagnose a sender jitter fault. As the fault lies with the user’s device, service providers can inform the manufacturer and request a change.
4. Only Capturing Relevant Data: Using Targeted Voice Monitoring To Preserve Resources
Voice monitoring makes it possible to record tremendous amounts of network traffic data, dumping gigabytes of information to disk for on-demand analysis. While data is a prerequisite to root cause analysis, storing too much can waste resources and even make life harder for troubleshooting teams. Often only a tiny fraction of the data recorded is relevant to the problem at hand, and employees must sift through a sea of noise to find the signal they are looking for.
A more innovative approach to voice monitoring is to analyze RTP packets in real-time and discard them once any relevant information has been extracted. If further information is required, probes can be triggered to record and store media stream packets.
This targeted approach to capturing data offers the best of both worlds. Resources aren’t wasted storing meaningless data, but when a thorough investigation is required, service providers have all the evidence they need. For example, in order to demonstrate faulty equipment to vendors.
Additionally, recording full RTP packets can be triggered automatically based on the quality of a media stream. For example, a probe examines an RTP packet and finds poor-quality call metrics below a certain threshold defined by the service provider. The probe can automatically begin capturing additional information ready for troubleshooting and further inspection.
5. See the Forest, Not Just the Trees: Generating Statistics for Trunks, Routes, and Other Aggregates
Especially for troubleshooting, one needs to have data on individual calls—but call data does not provide an overview on the service performance. To see the forest and not just the trees you need tools that can group data together to generate meaningful and actionable statistics and KPIs. Typical traffic grouping and aggregation criteria for RTP streams and SIP signaling is shown below:
RTP grouping and aggregation
Dimensions by which to aggregate media plane KPIs should include:
- Probes
- Trunks
- Numbering plans
Grouping and aggregating by probes provides a local view on the data, e.g., the performance of individual points of presence. Trunks allow to group traffic relations between network elements, such as between interconnection SBCs, customers and access SBCs or in LTE networks between eNBs and SGWs. Lastly, grouping by numbering plan entries allows to create KPIs per origin and destination, e.g., to assess the quality of calls to or from Canada.
It is important to be consistent about the methodology defining KPIs for each group described above; only then can you directly compare performance based on the position in the network, the parties involved in the call, the originating country, or the specific LTE infrastructure they utilized.
This form of aggregation also allows CSPs to gather data for SLAs by defining a SIP trunk for each enterprise customer.
SIP grouping and aggregation
KPIs for the control plane are based on aggregating signaling information at a monitoring point. Signaling KPIs should be monitored based on the same dimensions as defined above for the media plane:
- Probe
- SIP trunk
- Numbering plan
Using the same dimensions allows reporting on signaling and media transport performance for the same entities.
6. Don’t Average Averages: Calculating Metrics and KPIs Right
Measurement and data analysis can wind up with many dead ends, failing to truly capture user experience. For example, depending on their severity and distribution, factors such as jitter or packet loss can significantly impact the user experience. But that is the key; you need to understand their severity and distribution to know if they create relevant problems for the user. This information is often obscured by traditional audio quality metrics averaged over an entire call.
For example, a five-minute call may have a high average MOS. But at the end of the call, a sudden drop in audio quality caused a party to hang up. If the poor service only occurs briefly at the end of the call, it won’t drag down the average significantly. It makes a huge difference if 100 packets are lost in a row or if the loss is distributed over ten minutes. Therefore, the average MOS, just like many other average metrics, fails to capture the user experience, leading to problems going unsolved and unhappy customers.
Service providers need to go deeper than just averaging call quality metrics. They need information with high temporal resolution that tracks user experience across an entire call. Voice monitoring solutions are available with time-slicing technology analyzing the RTP stream throughout the call to pinpoint impairments in real-time.
7. Sharing Is Caring: Use the Data Throughout Your Organization
The value of data generated through voice monitoring increases when it is shared across the entire organization. With people from different teams accessing call-level data, organizations receive new opinions and uncover additional insights. Siloing data within specific teams limits potential, prevents innovation and does not help with introducing novel AI/ML-tools.
Voice monitoring data is relevant to the operations of many different teams:
- Technical teams need it for reporting, troubleshooting, and solving network issues
- Performance optimization teams want to use voice monitoring data to understand and enhance the user experience
- Sales and marketing teams can use voice monitoring information to attract potential customers and show SLA compliance for existing customers
- DevOps teams require a trusted source of service quality data to enable automation
Summary
With customer expectations going through the roof and significant competition to deal with, delivering excellent voice services has never been more critical. By following these best practices for voice monitoring, you will have the data needed to proactively spot network issues, remedying them before they impact user experience.
Additionally, you will have the tools fit for modern telecom operations. That means automation for enhanced data collection if performance drops, and root cause analysis—the capability to instantly identify common problems, drastically shortening the mean time to repair (MTTR).
The quickest way of following these best practices is to find a voice monitoring solution with the capacity for all seven. That is precisely what Voipfuture Qrsytal offers. Get in touch today to discover how Qrystal can transform how you see and manage your network.