Have you ever encountered a situation where your voice monitoring tool indicates optimal performance, yet customer complaints about voice quality persist? If so, you’re not alone in grappling with this mystery. Numerous Communication Service Providers (CSPs) have reached out to us throughout the years with similar frustrations, the perfect example that in such instances, ignorance is far from bliss.
Insufficient voice monitoring transcends mere technical glitches; it can be a direct blow to your business. Its repercussions extend to hindering productivity, escalating operational costs, and corroding customer trust. Achieving top-notch voice service performance isn’t just a daunting challenge; it stands as a fundamental competitive necessity.
In this article, I will delve into real-life examples and case studies that illuminate instances of voice quality issues, how to uncover the root causes and facilitate quicker resolutions and preventive measures. These cases serve as compelling illustrations of how the right data can streamline the troubleshooting process, resulting in significant time and effort savings. In some instances, the time required for resolution has been reduced by an impressive 80%, a figure that might even underestimate the potential efficiency gains.
By leveraging insightful data, businesses can rectify current problems more expediently as well as fortify their systems against future occurrences. This strategic approach not only enhances operational efficiency but also fosters a more resilient and reliable voice service infrastructure, ultimately contributing to sustained customer satisfaction and loyalty.
Case #1: My Monitoring Tool Says Everything Is Fine…
Let’s kick off with a classic scenario from the early days of our company. We received a call from someone requesting a Proof of Concept (POC), and the game-changing line in that conversation was, “My monitoring tool insists everything is fine, so why are my customers still grumbling?”
Now, take a peek at the image below – the existing voice monitoring system flashed green for good quality in both directions of this call example. Yet, the complaints persisted.

We came in with our own system, Qrystal. Take a look at the data it brought to the table for the same call:

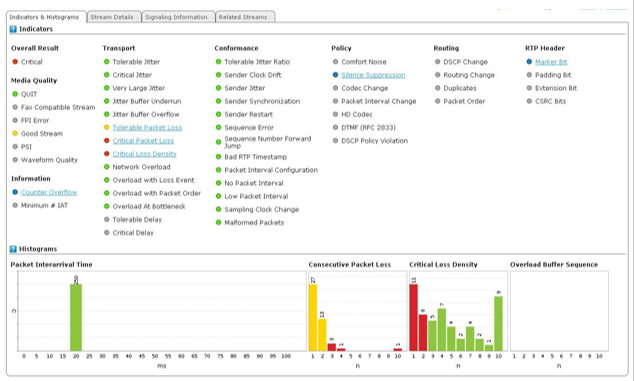
The data is the same in one direction, but different in the other. Qrystal didn’t sugarcoat it. Instead of the expected 4.2, it showed a dismal minimum MOS of just 1.42. That’s a massive gap, and I’m sure you’d all nod in agreement. A MOS of 1.42 is outright awful, and even though the average seems okay, it actually validates customers’ complaints.
Now, how come we see such a difference? Most tools don’t bother with the nitty-gritty of RTP traffic. Therefore, there’s a huge gap between the measurements or the data that they present and the reality that customers experience.
If your tool is saying that everything is fine, the investigation on this particular tool is pretty much over and you now need to invest a lot of time and effort to further investigate the case by yourself. Now imagine you had a different tool that provides you with plenty of additional data that saves you all this detective legwork. It not only confirms the service degradation during the call but also pinpoints exactly when it happened and possibly even where and why. This makes the journey to successful troubleshooting a whole lot simpler and quicker.
Without going too deep into the techy stuff, just know that when you use time slicing, you’re not just averaging things out. Instead of looking at the entire call, you slice it into bits. This way, you know precisely when the glitch hit, how intense it was, how long it lingered, and the impact it had on your users’ experience. Unfortunately, many tools out there lean on unreliable or even inaccurate data from endpoints or network elements, which don’t provide any meaningful insights.
Case #2: When You Don’t Even Know There Is Something to Fix
This case, looking back, is very funny, especially considering it happened during a POC at a major Tier-1 Communication Service Provider (CSP). Our mission was to set up a probe at a crucial site, monitoring traffic to and from other Points of Presence (POPs). The CSP anticipated a dashboard painted in a serene dark green, symbolizing flawless quality. However, reality painted a more vibrant picture – a canvas of red, yellow, and light green, hinting at an anomaly in one specific site, as illustrated below:
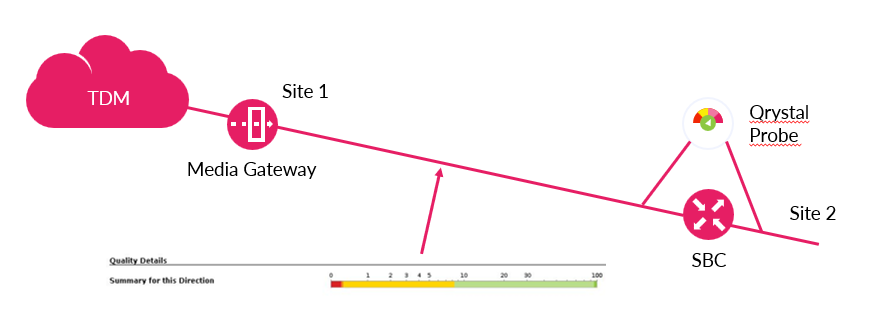
Upon closer inspection, we discovered that the Real-time Transport Protocol (RTP) streams between the two POPs were plagued by frequent bursts of packet losses, impacting all streams simultaneously, as depicted in the graph:
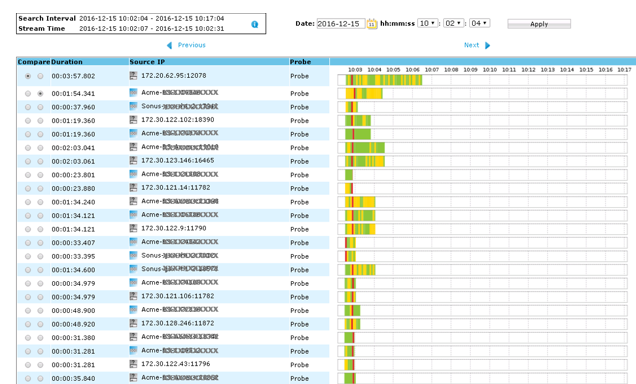
Each line mirrored an RTP stream, featuring the familiar traffic light pattern. The expectation was a sea of green, but reality unfolded in hues of red and yellow. The red line cascading from top to bottom signaled a pervasive issue affecting all streams consistently.
When we shared these revelations with the CSP’s operations team, their response was defensive: “It’s our core network; we don’t believe you. We would have noticed if something was indeed wrong.” Fortunately, armed with more detailed data, we substantiated our initial findings and exposed the root cause: severe loss without jitter, indicating a physical issue such as cracked fibers, dirty fibers or defective Small Form-Factor Pluggables (SFPs). The investigation ultimately unveiled a broken link, and the problem was promptly fixed.
Case #3: Three Days Instead of Three Months
Remember I mentioned at the beginning that an 80% reduction in fix time can be underestimated? This case vividly exemplifies this notion, revealing a scenario resolved in just three days with the right data, whereas a consortium of vendors struggled for three months without success. The challenge at hand was a formidable one – the perplexing issue of one-way audio. Without the right data, tackling such a problem is akin to navigating uncharted waters.
One of the largest CSPs in Europe, with millions of customers, onboarded an enterprise customer. The enterprise client voiced persistent complaints from the outset of their onboarding. The complaint centered around the calling party frequently being inaudible, with no discernible pattern related to the time of day or caller identity. The enterprise diligently reported and documented incidents, prompting a task force comprising vendors like Cisco, Acme, and incumbent monitoring solutions to grapple with the enigma.
The below image showcases statistics from December 12 to December 20, revealing a concerning frequency of dozens of reported calls per week. (Spoiler alert: once the pattern was identified, it became clear that the reported calls only amounted to about 4% of the total cases).
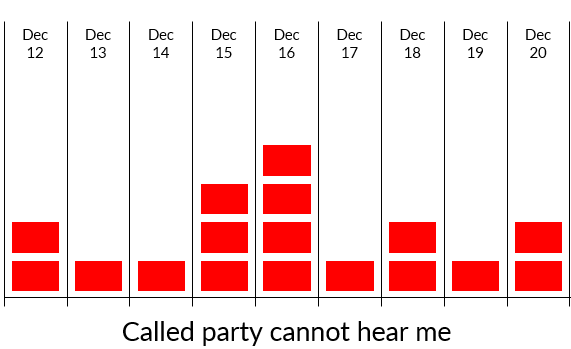
Upon our intervention, a glaring anomaly surfaced merely by inspecting the reported calls. As it turned out, each reported call had an accompanying unexpected second stream. Both streams shared identical start times, durations, destinations, and port numbers.
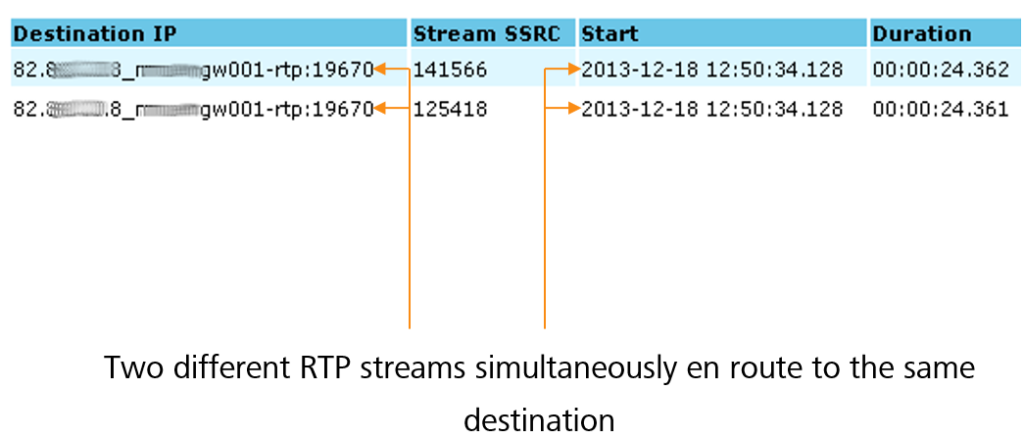
Further investigation exposed a bug in the Cisco Call Manager. In some cases, when an earlier call concluded, the associated RTP stream persisted, transmitting only silence. Dubbed “zombie streams,” these silent streams perpetuated until the Call Manager rebooted, never truly ending. If a new call is initiated to the same media gateway on the same port, the zombie stream could slip through the firewall or Session Border Controller (SBC). The receiver, unaware of what to expect, erroneously selected the first stream received, typically the zombie stream. While signaling appeared flawless and proper speech was exchanged in both directions, the receiver’s selection issue resulted in a one-way audio scenario.
From a data and monitoring standpoint, the critical insight lies in these zombie streams being invisible to conventional tools. Traditional monitoring tools recognize RTP packets only within a call context. Yet, the call context for these zombies had long vanished, leaving only RTP and nothing else in their wake.
Case #4: The Missing Link
This case stands out as one of the most intricate and unconventional challenges I’ve ever tackled, and, interestingly, it also revolves around a one-way audio issue.
The story unfolds at a top-ranked German radio station, a prominent client of a Tier-1 service provider. Renowned for its effective promotions, this station’s wide audience significantly contributes to its success. Audience reach, measured semi-annually by an external agency, plays a pivotal role in determining ad rates. Hence, during these measurement periods, maximizing audience reach becomes paramount.
In February 2018, the radio station initiated a riddle game, promising a €50K prize for callers who could solve it. The catch? Callers were instructed to dial a phone number explicitly excluded from use in mass-calling events. Complaints flooded in as listeners struggled to establish connections, prompting the service provider to start an investigation. Disturbingly, severe degradations of service availability occurred precisely five times a day – the slots designated for the riddle game. The overload not only affected those calling the radio station but also everyone connected to the impacted switch, creating a system-wide strain.
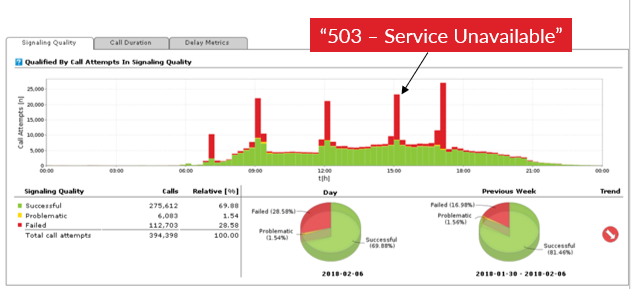
It just so happened that an unrelated government agency, employing 100K people, faced one-way audio and call drop issues around the same time. Frustration mounted as the agency bombarded the CSP with numerous tickets.
Unaware of any link between the incidents, two independent teams at the CSP launched investigations. The radio team traced the overload to calls to the same problematic number, prompting a resolution by recommending a different number for the radio station. Case closed. Or so it seemed.
Concurrently, the agency team delved into reported issues, suspecting network problems but perplexed by one-way audio issues during the same specific time slots. The absence of ticket bursts post-number change raised more questions – after all, the agency team wasn’t even aware of the issue with the radio station. This triggered a deeper investigation with Voipfuture’s support, which uncovered the link caused by a cascade of issues. Massive call attempts led to switch and media gateway overloads, resulting in “service 503 unavailable” error messages. The confused media gateway then emitted non-standard RTP streams, causing one-way audio for some clients.
Why some? Why was the agency hit so hard while others connected to the same media gateway faced fewer issues? The critical factor was the occurrence of sender restarts within these perplexed media gateways. A sender restart refers to a situation where the sequence number fails to increment systematically with each RTP packet. In the midst of the data flow, the sequence number resets, causing a simultaneous impact on all streams.
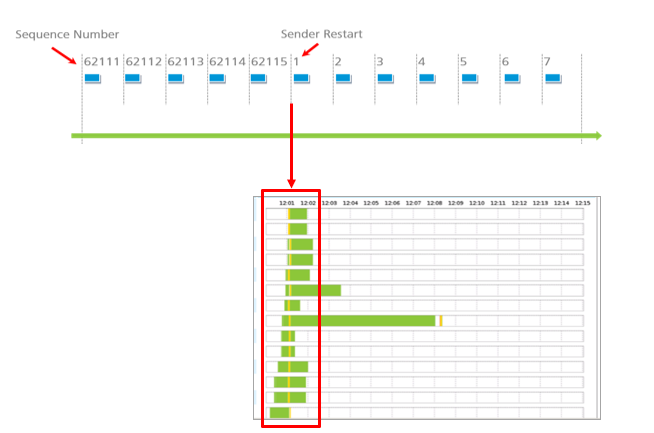
All streams experience the sender restart, initiating sequence numbers from one. While some longer calls persist, others are swiftly terminated. This inconsistency poses a challenge because the standard RFC 3550 doesn’t provide guidance on how a receiver should respond to such a sender restart. Typically, receivers utilize these sequence numbers to identify packet loss; if there’s a gap in the series, the receiver recognizes lost packets and can initiate packet loss concealment. However, in the absence of a wraparound mechanism for overflowing numbers, uncertainty arises when the sender restarts in the middle of the stream. The receiver faces the ongoing dilemma of whether to play out the audio or disregard the packet, awaiting the one with the correct sequence number.
The unique twist in this tale was the agency’s severe impact, attributed to devices from a specific vendor being overly discerning and ignoring packets during sender restarts. This incident underscores the critical role of data for saving time and resources. This complex case serves as a compelling reminder of the indispensability of comprehensive monitoring tools in resolving intricate network issues efficiently.
Final Thoughts
The journey through the intricacies of voice monitoring has illuminated the critical role it plays in the efficiency and resilience of communication networks. From uncovering hidden voice quality issues to swiftly resolving perplexing one-way audio challenges, the right data proves to be the linchpin in troubleshooting and preemptive measures. The cases presented underscore the tangible impact of advanced monitoring tools.
In a landscape where customer satisfaction and loyalty hinge on seamless communication experiences, the insights shared in these real-life scenarios serve as a beacon, guiding businesses toward a future where proactive monitoring ensures uninterrupted and superior voice services.